New Features
Run CORE in your environment (Gateway)- You can now run tools through a self-hosted Gateway, so CORE can take actions inside your network and with your local setup.
- This also unlocks longer-running workflows that can continue in the background instead of timing out mid-run.
- CORE’s email and WhatsApp handling is now built on a unified “channel” system, so message delivery, history, and follow-ups behave more consistently across surfaces.
- This is the foundation for doing the same across more channels going forward.
- You can now use CORE from Slack via DMs and channel mentions.
- Threads are tracked as separate conversations, which keeps context clean when multiple topics are happening in the same channel.
- You can now create multiple workspaces under one account to keep different contexts (work, personal, clients) cleanly separated.
- Atlassian (Jira + Confluence): Connect via OAuth and let CORE pull in tickets, docs, and knowledge without manual copy/paste.
- Ghost: Manage posts/pages/tags via the Ghost Admin API so publishing workflows can be automated.
- LinkedIn: Fetch profile and activity context for networking and outreach workflows.
- Codeberg: A Git-hosting integration with growing parity to GitHub (issues, PRs, labels, and repo content).
- CORE can now run “skills” — structured, reusable workflows — so common tasks (research, outreach, triage, recurring ops) become repeatable playbooks.
Performance & Reliability
- Slack webhooks: Slack DM bot verification now runs asynchronously, avoiding Slack’s 3-second timeout failures.
- Reminders: Reminder execution was refactored onto a centralized pipeline for more consistent scheduling and delivery.
Improvements
- GitHub + Codeberg automation: Better automation parity (including richer issue creation flows and more repo operations) so agents can complete tasks without manual cleanup.
- Search V2 (multi-workspace): Workspace resolution was hardened so search returns results reliably in multi-workspace setups.
- Timezone correctness: Agent datetime context now respects the user’s timezone, reducing “wrong day / wrong time” outcomes.
- Setup clarity: Added concrete ingestion rule examples across integrations so initial configuration is less guessy.
Fixes
- Channels: Fixed cases where creating a conversation failed for external channels (including email edge cases).
- Slack: Fixed broken inbound Slack processing.
- OAuth: Fixed PKCE handling for OAuth flows.
- Gateway: Fixed browser handoff failures during gateway-driven browser flows.
- Search V2: Fixed exploratory search returning nothing when label routing didn’t find a match.
Security & Privacy
- Skills: Prevented skill documents from being exposed via the document APIs.
🎯 New Features
Claude Code Plugin- Native CORE integration for Claude Code via MCP
- Access your memory and take actions directly from your terminal
- Seamlessly connect CORE’s knowledge graph to your coding workflow
- Advanced v2 search powered by an intelligent agent orchestrator
- Faster, more precise retrieval from your knowledge graph
- Better understanding of complex queries with multi-step reasoning
- Todoist: Task management actions from any AI agent
- Google Tasks: Manage to-dos across Google Workspace
- Auto-create Google integrations on signup for faster setup
- Build custom integrations and tools on top of CORE
- Programmatic access to memory, search, and actions
- Extend CORE’s capabilities for your specific workflows
- Smarter user profiles that understand context across 11 aspects
- More accurate representation of your work patterns and preferences
- Better AI responses tailored to how you actually work
⚡ Performance & Reliability
- Faster Search: Agent orchestrator architecture for 2-3x speed improvement
- Optimized Knowledge Graph: Enhanced entity resolution and relationship mapping
- Better Session Compaction: Improved prompt compression for efficient memory storage
- Vector Similarity Ordering: More relevant results from semantic queries
🔧 Improvements
- Simpler Onboarding: Streamlined setup flow with fewer steps
- Multiple Tool Approval: Handle batch tool requests in a single approval flow
- Better Slack Handling: Support for multiple account events and message arrays
- Enhanced Authentication: Clearer completion messages and status updates
- Webhook Raw Events: Access to raw event data for custom processing
🐛 Fixes
- Resolved 502 errors from synchronous integration tool execution
- Fixed persona document ingestion log handling
- Corrected onboarding agent ID passing
- Fixed search v2 error handling
- Resolved document editing assertion issues
- Fixed Gmail thread userId parameter
- Corrected session compaction sessionId handling
- Fixed documentId vs sessionId confusion
- Improved Google OAuth scope handling
🎯 New Features
Labels System (Migration from Neo4j to Postgres)- Labels now stored in Postgres for faster access and updates
- Document table as single source of truth for better consistency
- Improved label assignment and management across workspace
- Track DORA metrics (deployment frequency, lead time, change failure rate, MTTR)
- Engineering insights and productivity analytics
- Date range comparisons and period-over-period analysis
- Native Linear issue management via MCP
- Slack messaging and channel actions through MCP
- Unified access across all your AI agents
- Improved handling of broad, exploratory queries
- Search entire conversation episodes for better context
- Enhanced recall quality for complex information needs
- Self-host CORE with a single click
- Official Railway deployment support
- Production-ready configuration out of the box
⚡ Performance & Reliability
- Persona Generation Migration: Moved to Postgres for faster profile updates
- Knowledge Graph Improvements: More relationship-focused structure
- Vector Storage Enhancements: Added ingestionQueueId, labelIds, sessionId tracking
- Dual-Queue System: Trigger.dev + BullMQ for reliable integration execution
🔧 Improvements
- Alfred Persona: Enhanced agent system prompt for more natural conversations
- Session & Episode Deletion: Full control over conversation history
- Simplified Logs: Cleaner, more readable activity tracking
- Proactive AI: Chat prompts emphasize cross-tool intelligence and temporal awareness
- Mobile UI: Improved Gmail integration page responsiveness
🐛 Fixes
- Fixed ingestion queue deletion cascades
- Resolved document update latency issues
- Corrected Zoho integration authentication
- Fixed PostHog proxy connection errors
- Resolved Python 3.9 datetime parsing compatibility
- Fixed new conversation integration failures
- Corrected GitHub analytics date filtering
🔒 Security & Privacy
- Better Data Isolation: Improved workspace and label scoping
- Enhanced OAuth Flows: More secure Google integration setup
- MCP Session Handling: Proper namespace isolation and sessionId management
🎯 New Features
Google Workspace Integrations- Gmail: Read, search, and send emails from any AI agent
- Google Sheets: Update spreadsheets and analyze data
- Google Docs: Access and edit documents programmatically
- AI-generated user profiles based on your memory and conversations
- Automatically surfaces your preferences, patterns, and work style
- Helps AI agents provide more personalized and contextual responses
- Codex, Gemini CLI, Windsurf, ChatGPT, and 13 more providers
- Connect CORE memory to your preferred AI tools
- Unified onboarding flow for faster provider setup
- Zoho Mail: Email management for Zoho users
- Notion: Access workspace pages and databases
- Cal.com: Calendar scheduling and meeting management
- Automatically compress conversations after 3 exchanges
- Preserve important context while reducing memory footprint
- Smarter long-term recall without losing key information
- Advanced reranking for more precise episode retrieval
- Better result ordering based on semantic relevance
- Improved search quality across all query types
⚡ Performance & Reliability
- Optimized Ingestion: Faster document processing and knowledge graph updates
- Entity Deduplication: Exact name matching before LLM resolution (2-3x faster)
- Vector Search Optimization: Improved candidate retrieval across all graph models
- Episode Retrieval: Exclude embeddings from queries for faster results
- GDS Cosine Similarity: Replaced vector index queries for better performance
🔧 Improvements
- Mobile-Friendly Product: Fully responsive interface for mobile devices
- Enhanced Onboarding: Added skip button and improved flow persistence
- Recency Sorting: Time-based filtering and entity-based search
- MCP Specification Compliance: More complete and standards-compliant MCP server
- GitHub Community Manager Skill: Pre-built skill for community management workflows
🐛 Fixes
- Fixed persona generation threshold checking
- Resolved integration tool failures
- Corrected episode and document deletion handling
- Fixed recall deduplication issues
- Resolved embedding size validation
- Fixed document title regeneration
- Corrected label assignment in persona generation
- Fixed session compaction timing
- Resolved OAuth2 form responsiveness
- Fixed domain cookie handling for the non-HTTPS
- Corrected MCP session_id failures
🎯 New Features
Deep Search- Advanced search capability for Browser Extension and Obsidian
- Surface insights from your memory with greater precision and context
- Connect related information across different sources more effectively
- Once-click full account deletion with complete data cleanup
- Automatic removal of all data from both PostgreSQL and Neo4j graph databases
- Peace of mind with complete data control and privacy management
- New guided flow for faster setup and first memory ingestion
- Direct integration setup via MCP configuration links
- Automatically summarizes long conversations for efficient memory storage
- Compacted sessions now appear in search with Markdown formatting
- Improves long-term recall without losing important context
- Connect your own AWS Bedrock account for AI model access
- Choose from Claude, Titan, and other AWS models
- Greater flexibility in model selection and deployment options
⚡ Performance & Reliability
Faster, more stable experience- Improved Search Quality: Structured, faster, and more relevant results
- Optimized Graph Performance: Reduced iterations for quicker retrieval
- Better Memory Recall: Session compaction models improve long-term context retention
- Streamlined Credit Management: Proper error handling when credits are exhausted
🔧 Improvements
-
Labels (Migration from Spaces):
- Complete migration from Spaces to Labels organizational model
- Workspace-scoped labels with Linear-style tagging
- Labels stored in PostgreSQL, scoped by workspace
- Episodes now use
labelIdsarray instead ofspaceIds - Multiple labels can be assigned to any episode
- Simplified label management via web interface and API
-
MCP Tooling:
- Clear error messages when credits run low
- Improved tool descriptions for better AI assistant understanding
- Resolved profile summary edge cases affecting MCP connections
🐛 Fixes
- Fixed API key deletion not working properly
- Resolved document view breaking in log viewer
- Fixed semantic search inconsistencies affecting result quality
- Resolved login attribute conflicts in authentication flow
- Fixed graph visualization issues in Chrome 140
- Corrected ingestion queue handling for deleted episodes
- Fixed MCP tool call failures for (
get_user_profile) - Resolved label description validation blocking label creation
🔒 Security & Privacy
Data protection updates- Complete Account Wipe: Account deletion now removes all traces from both relational and graph databases
- Cascade Delete Logic: Simplified deletion flows with proper relationship cleanup for users and workspaces
- Neo4j Graph Cleanup: Automated cleanup of knowledge graph nodes when deleting accounts
- Proper Resource Cleanup: Removes all associated API keys, labels, and episodes
🎯 New Features
Documents in Knowledge Graph- Full document context now stored in the knowledge graph
- Better relationship mapping between documents and conversations
- Enhanced cross-document search and recall
- Automatically generated topic summaries for your workspaces
- Quick overview of key themes and concepts in each space
- Easier navigation through large knowledge bases
- MCP tool for accessing user profile information
- AI agents can understand user profile information
- More personalized responses across all connected tools
- Save and persist onboarding answers
- Improved loading states and user feedback
- Faster time-to-first-memory
⚡ Performance & Reliability
- Optimized Entity Extraction: Enhanced prompts for better entity recognition
- Chunking Improvements: Reduced chunk size to 1-3k tokens for better precision
- Simplified Entity Resolution: Type-free handling for faster processing
- Increased Reranking Threshold: Better filtering of low-quality results
🔧 Improvements
- Activity UI Refresh: Cleaner activity tracking interface
- Document Logs Enhancement: New API for episode deletion
🐛 Fixes
- Fixed graph visualization issues in Chrome 140
- Resolved deleted episode ingestion queue handling
- Corrected MCP tool descriptions
- Fixed invalidated statement search queries
- Various onboarding and UI fixes
🎯 New Features
Capabilities users can now accessOrganization (Note: This feature evolved into Labels in later releases)- Organize your memory into project-specific contexts (Health, Personal, Work, Client Projects)
- Share memory contexts with team members for collaborative AI assistance
- Default user profile context with seamless node linking across projects
- New logs UI for tracking memory ingestion and retrieval
- Real-time visibility into MCP connections and integration status
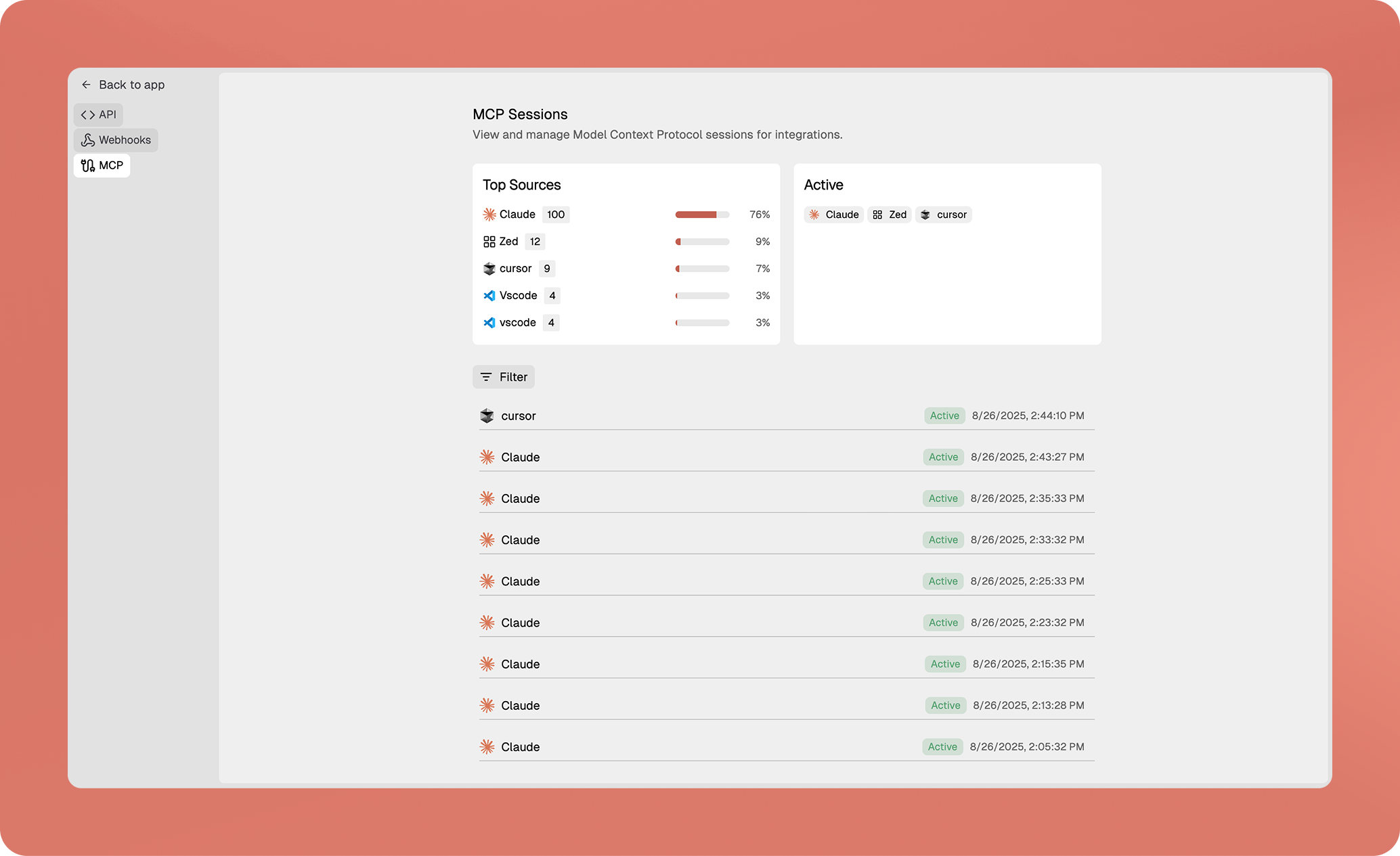
- Debug memory operations and optimize your workflow efficiency
- One-command self-hosting setup with improved configuration
- Better network isolation and service management
⚡ Performance & Reliability
Faster, more stable experience- Improved Recall Efficiency: Significantly better fact retrieval and relevance scoring
- Enhanced MCP Server Stability: Resolved mid-flight stream failures and connection drops
- Better Connection Management: 60-second ping intervals to maintain persistent connections
- Streamlined Integration Processing: Faster webhook event handling and memory updates
🔧 Improvements
Enhanced existing functionality- Enhanced MCP OAuth Scopes: Better integration support for Windsurf and other coding tools
- Refined Facts Page UI: Improved label-specific fact browsing and search
- Optimized Memory Tools: Better source tracking and metadata preservation
- Unified MCP Server: Single server instance handling all integrations for improved performance
🐛 Fixes
Resolved issues affecting user experience- Fixed MCP server stream failures that interrupted AI client connections
- Resolved OAuth scope issues affecting Windsurf integration
- Corrected source attribution problems in memory tools
- Fixed facts page access issues for label-specific content
- Resolved database dependency conflicts in trigger service deployment
🔒 Security & Privacy
Data protection updates- Enhanced OAuth Security: Improved token management and scope validation
- Better Integration Isolation: Cleaner separation between different app connections
- Secure Memory Attribution: Proper source tracking without exposing sensitive metadata
🎯 New Features
Capabilities users can now accessBrowser Extension- Seamlessly capture and organize web content directly into your CORE memory
- Right-click context menus for instant memory ingestion
- Never lose important research or documentation again
- One-click authentication for Linear, Slack, GitHub, and Notion
- Connect your tools once, access them everywhere across AI clients
- Eliminate repetitive app authentication across different AI platforms
- Transform CORE into your universal MCP gateway
- Connect apps once to CORE, then share access with Claude, Cursor, and other AI clients
- Multiplier effect: N apps × M clients through single authentication point
- Automatic capture of assigned Linear issues, Slack mentions, and GitHub activity
- Set custom rules for what gets remembered from your connected apps
- Your AI tools now have context about your actual work, automatically
- Temporal knowledge graph with reified statements as first-class objects
- Every piece of information includes provenance and meta-knowledge
- Living memory that evolves with your projects and preferences
⚡ Performance & Reliability
Faster, more stable experience- Improved Memory Ingestion Speed: Faster processing of large documents and web pages
- Enhanced Graph Relationships: More efficient storage and retrieval of connected information
- Streamlined Episode Management: Better handling of conversation context and memory episodes
🔧 Improvements
Enhanced existing functionality- Refreshed UI Components: Cleaner, more intuitive interface design
- Enhanced Loading Transitions: Smoother user experience during memory operations
- Improved Integration Flows: More reliable authentication and connection setup
- Better Docker Support: Simplified containerization for self-hosted deployments
🐛 Fixes
Resolved issues affecting user experience- Fixed fresh installation failures affecting new user onboarding
- Resolved Docker build workflow issues for self-hosted deployments
- Corrected activity flow and invalidation logic in knowledge graph
- Fixed UI component rendering issues across different browsers